14 07 2022
[July-2022]Exam Pass 100%!Braindump2go DP-500 Dumps DP-500 85Q Instant Download[Q27-Q50]
July/2022 Latest Braindump2go DP-500 Exam Dumps with PDF and VCE Free Updated Today! Following are some new DP-500 Real Exam Questions!
Question: 27
You use Azure Synapse Analytics and Apache Spark notebooks to You need to use PySpark to gain access to the visual libraries. Which Python libraries should you use?
A. Seaborn only
B. Matplotlib and Seaborn
C. Matplotlib only
D. Matplotlib and TensorFlow
E. TensorFlow only
F. Seaborn and TensorFlow
Answer: E
Question: 28
You are using a Python notebook in an Apache Spark pool in Azure Synapse Analytics. You need to present the data distribution statistics from a DataFrame in a tabular view. Which method should you invoke on the DataFrame?
A. freqltems
B. explain
C. rollup
D. summary
Answer: D
Question: 29
You have a kiosk that displays a Power Bl report page. The report uses a dataset that uses Import storage mode. You need to ensure that the report page updates all the visuals every 30 minutes. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Enable Power Bl embedded.
B. Configure the data sources to use DirectQuery.
C. Configure the data sources to use a streaming dataset
D. Select Auto page refresh.
E. Enable the XMIA endpoint.
F. Add a Microsoft Power Automate visual to the report page.
Answer: AD
Question: 30
You have an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that the SQL pool is scanned by Azure Purview. What should you do first?
A. Register a data source.
B. Search the data catalog.
C. Create a data share connection.
D. Create a data policy.
Answer: B
Question: 31
You have a Power Bl workspace that contains one dataset and four reports that connect to the dataset. The dataset uses Import storage mode and contains the following data sources:
• A CSV file in an Azure Storage account
• An Azure Database for PostgreSQL database
You plan to use deployment pipelines to promote the content from development to test to production. There will be different data source locations for each stage. What should you include in the deployment pipeline to ensure that the appropriate data source locations are used during each stage?
A. parameter rules
B. selective deployment
C. auto-binding across pipelines
D. data source rules
Answer: B
Question: 32
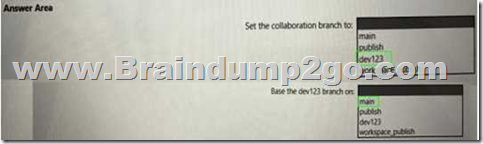
HOTSPOT
You need to configure a source control solution for Azure Synapse Analytics. The solution must meet the following requirements:
• Code must always be merged to the main branch before being published, and the main branch must be used for publishing resource
• The workspace templates must be stored in the publish branch.
• A branch named dev123 will be created to support the development of a new feature. What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

Answer:
Question: 33
You need to provide users with a reproducible method to connect to a data source and transform the data by using an Al function. The solution must meet the following requirement
• Minimize development effort.
• Avoid including data in the file. Which type of file should you create?
A. PBIDS
B. PBIX
C. PBIT
Answer: A
Question: 34
You are planning a Power Bl solution for a customer.
The customer will have 200 Power Bl users. The customer identifies the following requirements:
• Ensure that all the users can create paginated reports.
• Ensure that the users can create reports containing Al visuals.
• Provide autoscaling of the CPU resources during heavy usage spikes.
You need to recommend a Power Bl solution for the customer. The solution must minimize costs. What should you recommend?
A. Power Bl Premium per user
B. a Power Bl Premium per capacity
C. Power Bl Pro per user
D. Power Bl Report Server
Answer: A
Question: 35
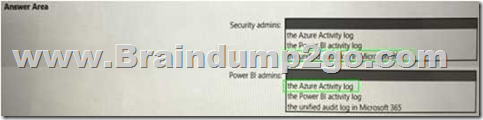
HOTSPOT
You need to recommend an automated solution to monitor Power Bl user activity. The solution must meet the following requirements:
• Security admins must identify when users export reports from Power Bl within five days of a new sensitivity label being applied to the artifacts in Power Bl.
• Power Bl admins must identify updates or changes to the Power Bl capacity.
• The principle of least privilege must be used.
Which log should you include in the recommendation for each group? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Answer:
Question: 36
You have a 2-GB Power Bl dataset.
You need to ensure that you can redeploy the dataset by using Tabular Editor. The solution must minimize how long it will take to apply changes to the dataset from powerbi.com.
Which two actions should you perform in powerbi.com? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point
A. Enable service principal authentication for read-only admin APIs.
B. Turn on Large dataset storage format.
C. Connect the target workspace to an Azure Data Lake Storage Gen2 account.
D. Enable XMLA read-write.
Answer: D
Question: 37
You have five Power Bl reports that contain R script data sources and R visuals.
You need to publish the reports to the Power Bl service and configure a daily refresh of datasets. What should you include in the solution?
A. a Power Bl Embedded capacity
B. an on-premises data gateway (standard mode)
C. a workspace that connects to an Azure Data Lake Storage Gen2 account
D. an on-premises data gateway (personal mode)
Answer: D
Question: 38
You have new security and governance protocols for Power Bl reports and datasets. The new protocols must meet the following requirements.
• New reports can be embedded only in locations that require authentication.
• Live connections are permitted only for workspaces that use Premium capacity datasets.
Which three actions should you recommend performing in the Power Bl Admin portal? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. From Tenant settings, disable Allow XMLA endpoints and Analyze in Excel with on-premises datasets.
B. From the Premium per user settings, set XMLA Endpoint to Off.
C. From Embed Codes, delete all the codes.
D. From Capacity settings, set XMLA Endpoint to Read Write.
E. From Tenant settings, set Publish to web to Disable.
Answer: A
Question: 39
You have an Azure Synapse Analytics serverless SQL pool.
You need to catalog the serverless SQL pool by using Azure Purview.
Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Create a managed identity in Azure Active Directory (Azure AD).
B. Assign the Storage Blob Data Reader role to the Azure Purview managed service identity (MSI) for the storage account associated to the Synapse Analytics workspace.
C. Assign the Owner role to the Azure Purview managed service identity (MSI) for the Azure Purview resource group.
D. Register a data source.
E. Assign the Reader role to the Azure Purview managed service identity (MSI) for the Synapse Analytics workspace.
Answer: ACD
Question: 40
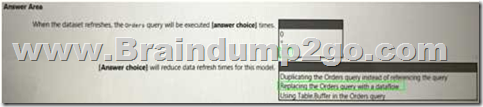
HOTSPOT
You have a Power Bl dataset that has the query dependencies shown in the following exhibit.
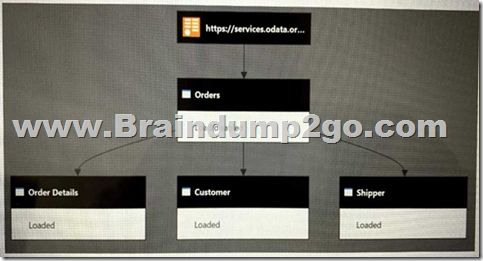
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
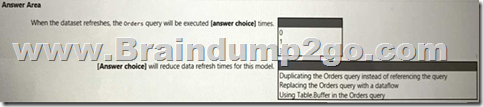
Answer:
Question: 41
DRAG DROP
You are configuring Azure Synapse Analytics pools to support the Azure Active Directory groups shown in the following table.

Which type of pool should each group use? To answer, drag the appropriate pool types to the groups. Each pool type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Answer:

Question: 42
You are running a diagnostic against a query as shown in the following exhibit.
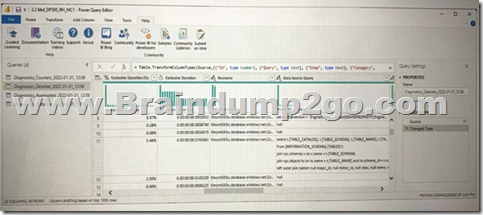
What can you identify from the diagnostics query?
A. All the query steps are folding.
B. Elevated permissions are being used to query records.
C. The query is timing out.
D. Some query steps are folding.
Answer: D
Question: 43
HOTSPOT
You use Advanced Editor in Power Query Editor to edit a query that references two tables named Sales and Commission. A sample of the data in the Sales table is shown in the following table.

A sample of the data in the Commission table is shown in the following table.

You need to merge the tables by using Power Query Editor without losing any rows in the Sales table.
How should you complete the query? To answer, select the appropriate options in the answer are
a.
NOTE: Each correct selection is worth one point.

Answer:

Question: 44
You are creating an external table by using an Apache Spark pool in Azure Synapse Analytics. The table will contain more than 20 million rows partitioned by date. The table will be shared with the SQL engines.
You need to minimize how long it takes for a serverless SQL pool to execute a query data against the table.
In which file format should you recommend storing the table data?
A. JSON
B. Apache Parquet
C. CSV
D. Delta
Answer: C
Question: 45
You have a Power Bl dataset named Dataset1 that uses DirectQuery against an Azure SQL database named DB1. DB1 is a transactional database in the third normal form.
You need to recommend a solution to minimize how long it takes to execute the query. The solution must maintain the current functionality. What should you include in the recommendation?
A. Create calculated columns in Dataset1.
B. Remove the relationships from Dataset1.
C. Normalize the tables in DB1.
D. Denormalize the tables in DB1.
Answer: C
Question: 46
You are building a Power Bl dataset that will use two data sources.
The dataset has a query that uses a web data source. The web data source uses anonymous authentication.
You need to ensure that the query can be used by all the other queries in the dataset. Which privacy level should you select for the data source?
A. Public
B. Organizational
C. Private
D. None
Answer: C
Question: 48
After you answer a question in this section, you will NOT be able to return to it. As a result, these
questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8- encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.

You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend using openrowset with to explicitly define the collation for businessName and surveyName as Latim_Generai_100_BiN2_UTF8.
Does this meet the goal?
A. Yes
B. No
Answer: A
Question: 49
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8- encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.

You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend using openrowset with to explicitly specify the maximum length for businessName and surveyName.
Does this meet the goal?
A. Yes
B. No
Answer: B
Question: 50
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8- encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.

You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend defining a data source and view for the Parquet files. You recommend updating the query to use the view.
Does this meet the goal?
A. Yes
B. No
Answer: A
Resources From:
1.2022 Latest Braindump2go DP-500 Exam Dumps (PDF & VCE) Free Share:
https://www.braindump2go.com/dp-500.html
2.2022 Latest Braindump2go DP-500 PDF and DP-500 VCE Dumps Free Share:
https://drive.google.com/drive/folders/1lEn-woxJxJCM91UMtxCgz91iDitj9AZC?usp=sharing
3.2021 Free Braindump2go DP-500 Exam Questions Download:
https://www.braindump2go.com/free-online-pdf/DP-500-PDF(42-62).pdf
https://www.braindump2go.com/free-online-pdf/DP-500-PDF-Dumps(1-20).pdf
https://www.braindump2go.com/free-online-pdf/DP-500-VCE-Dumps(21-41).pdf
Free Resources from Braindump2go,We Devoted to Helping You 100% Pass All Exams!
[July-2022]Exam Pass 100%!Braindump2go 312-49v10 Dumps VCE 312-49v10 769Q Instant Download[Q701-Q752] [July-2022]100% Success-Braindump2go 300-810 Exam Questions PDF 300-810 218Q Instant Download[Q183-Q204]
Comments are currently closed.